Linux SDK 文档
1、简介
与语音听写相反,语音合成是将一段文字转换为语音,可根据需要合成出不同音色、语速和语调的声音,让机器像人一样开口说话。
合成详细的接口介绍及说明请参考: MSC Linux API 文档 ,在集成过程中如有疑问,可登录讯飞开放平台论坛 ,查找答案或与其他开发者交流
小语种及少数民族方言:需使用UTF8编码方式!
#2、SDK集成指南
#2.1 Demo运行步骤
1.在控制台下载对应sdk
2.进入sdk内samples/tts_online_sample目录source 64bit_make.sh或32bit_make.sh, 视系统位数选择
3.运行成功后进入sdk bin目录下cd ../../bin/,运行./tts_online_sample即可看到运行结果
#2.2 项目集成步骤
#2.2.1 sdk包说明
《SDK目录结构一览》
- bin:
- msc(生成msc日志)
- wav(符合标准的音频文件样例)
- 相关资源文件
- doc:
- 相关技术文档
- include:
- 调用SDK所需头文件
- libs:
- x86/libmsc.so(32位动态库)
- x64/libmsc.so(64位动态库)
- samples:
- tts_online_sample(语音合成示例)
注意:
- 为了减少SDK包在应用中占用的大小,官网在下载单个功能的SDK包时, 可能并不包含其他功能,如下载合成的SDK包时,可能不包含听写或唤醒等功能,因此在运行未包含功能的示例时,可能会报错。对此请下载对应功能的SDK,或下载组合的SDK包。
#2.2.2 sdk导入
- 新建目录Demo,将SDK中bin,include,libs文件夹复制到新建工程“Demo”文件夹下
- 在demo目录新建文件demo.c,详细源码请参考samples中对应的语音示例
- 在demo目录下,创建Makefile文件,具体参见samples下的Makefile,修改路径和目标文件即可
- 将samples目录下“32bit_make.sh”文件或者“64bit_make.sh”文件拷到demo目录下,修改libmsc.so库搜索路径
- cd到demo目录下,执行“source 32bit_make.sh”或者 “source 64bit_make.sh”完成编译
- cd到bin目录下运行目标文件,SDK启动后,bin/msc目录下会生成日志(注意:msc文件夹下需有msc.cfg文件)
#2.2.3 API调用流程
语音合成主要API调用流程如下图所示:
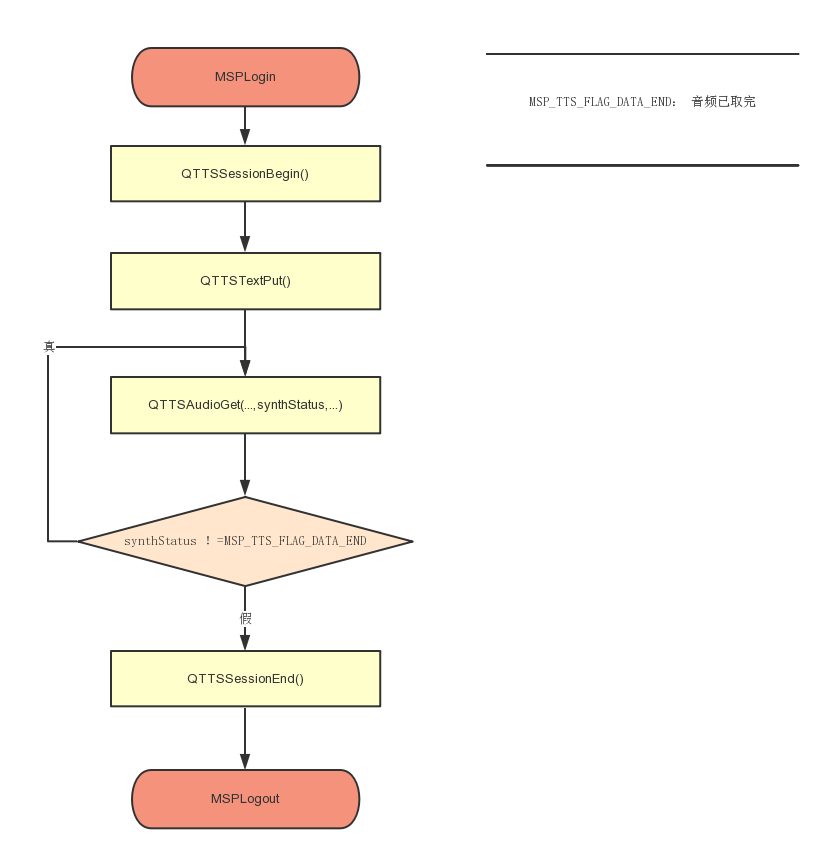
详细代码调用请参考 Samples中的 tts_sample(语音合成示例),API详细描述请参考API文档
#2.3 参数与说明
以下所述针对在线合成引擎,如需离线合成,请点击这里
在线引擎(TYPE_CLOUD),又称为云端模式,需要使用网络,速度稍慢,并产生一定流量,但有更好的合成效果,更多的发音人等。在线引擎下,结果返回速度基本决定于用户网络的带宽限制。
#2.3.1 代理服务器设置
在MSPLogin接口的params参数中添加:
net_type=custom, proxy_ip=<host>, proxy_port=<port>
其中,<host>,<port>替换为实际的代理服务器地址和端口。
例如:MSPLogin(NULL, NULL, "appid = 12345678, net_type=custom, proxy_ip=192.168.1.2, proxy_port=8080"); 注意:各参数间,以英文逗号分隔。
接口原型: int MSPLogin(const char* usr, const char* pwd, const char* params)
注意: 若在设置代理参数后,使用语音服务过程中,报错10204/10205/10212等网络异常错误时,请查阅以下内容,做出相关操作:
- 讯飞语音SDK的通信协议使用的是标准HTTP1.1协议,其代理协议使用的是标准HTTP代理协议。
- 代理服务器需要支持全双工多问多答方式,即 pipeline 模式。
- 代理服务器不能对80端口做限制,不能对如下域名做拦截: hdns.openspeech.cn scs.openspeech.cn open.xf-yun.com dev.voicecloud.cn
- 需要确保代理服务器只负责转发数据包,不能改变数据包的完整性和时序性。
- 代理服务器在转发数据包时,不能在HTTP协议头部添加 IE6 标识头。
#2.3.2 在线发音人说明
合成发音人列表请到控制台-我的应用-语音合成-在线语音合成(流式版)-发音人授权管理处查看,部分发音人支持添加试用,添加后即可查看发音人参数值:
- 语言为中英文的发音人可以支持中英文的混合朗读。
- 英文发音人只能朗读英文,中文无法朗读。
- 汉语发音人只能朗读中文,遇到英文会以单个字母的方式进行朗读。
- 支持新引擎参数的发音人,使用新引擎参数可以获得更好的合成效果。
#2.3.3 常用参数说明
以下为常用参数说明,更多参数请参考API文档
| 参数 | 名称 | 说明 |
|---|---|---|
| voice_name | 发音人 | 不同的发音人代表了不同的音色,如男声、女声、童声等,详细请参照控制台发音人列表 |
| speed | 语速 | 合成音频对应的语速,取值范围:[0,100],数值越大语速越快。默认值:50 |
| volume | 音量 | 合成音频的音量,取值范围:[0,100],数值越大音量越大。默认值:50 |
| rdn | 数字发音 | 合成音频数字发音,支持参数, 0 数值优先, 1 完全数值, 2 完全字符串, 3 字符串优先, 默认值:0 |
| background_sound | 背景音 | 合成音频中的背景音,支持参数,0:无背景音乐,1:有背景音乐 |
| sample_rate | 合成音频采样率 | 合成音频采样率,支持参数,16000,8000,默认为16000 |
#3、常见问题
#错误码及相应解决方案查询网址
答: 错误码及相应解决方案查询
#arm架构如何使用SDK?
答:默认提供的只有X86的so库,arm和mips架构请提交交叉编译工单,需单独收费。
#拿到了合成音频但不知道如何来播放
答:拿到的合成音频是没有音频头的,音频头中含有音频格式、采样率、音频长度等播放音频所需信息。拿到合成音频后,用户可以添加音频头,可参考例子tts_sample中的代码,然后使用常规播放器来播放;也可以使用Cool Edit等软件手动选择音频参数来播放。
#如何进行大文本的合成
答:语音云一次语音合成允许的合成文本大小不超过8192个字节,所以对于长度超过此值的大合成文本,用户可以采用“分段合成”的方式,即先将大文本按照标点符号如句号进行切分,然后对每一段文本分别进行合成。进行分段合成时,用户既可以在一路会话中循环使用QTTSTextPut+QTTSAudioGet组合完成合成,也可以为每一段文本使用一路独立的会话完成合成。
#如何设置语音云服务URL
答:在MSPLogin接口中添加:server_url = http://YourDomainName/msp.do (YourDomainName是指语音云服务域名,请开发者自行替换) 例如:MSPLogin(NULL, NULL, "appid = 12345678, server_url = http://sdk.openspeech.cn/msp.do"); 注意:各参数间,以英文逗号分隔。 接口原型: int MSPLogin(const char* usr, const char* pwd, const char* params)