Android SDK 文档
1、简介
语音听写,是基于自然语言处理,将自然语言音频转换为文本输出的技术。语音听写技术与语法识别技术的不同在于,语音听写不需要基于某个具体的语法文件,其识别范围是整个语种内的词条。
自2019/8/16起,高阶功能-动态修正免费开放!可到这里 动态修正效果 在线体验
使用方法详见 动态修正
在听写时,可以上传个性化的词表,如联系人列表等,提高列表中词语的匹配率(详情见个性化热词设置)。
语音听写详细的接口介绍及说明请参考: MSC Android API 文档 。
在集成过程中出现错误,请优先查询SDK&API 错误码查询 。如有疑问,请提交工单 进行咨询,也可登录讯飞开放平台论坛 与广大开发者共同学习和交流。
小语种:
- 目前小语种已经适配日语、俄语、西班牙语、法语、韩语,其他小语种敬请期待!
#2、SDK集成指南
#2.1、Demo运行步骤
根据官网控制台 提示,直接下载SDK,SDK中包含简易可运行的Demo。如下图所示: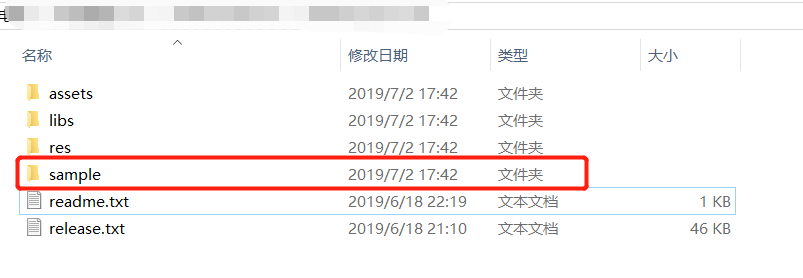
备注:Android sdk目前支持android4.4及以上系统,同时建议真机调试。
下载完SDK后,解压至相应的路径,以Android Studio集成开发工具为例,测试时建议直接用真机进行测试。
#方法一(导入project方式):
打开Android Studio,在菜单栏File--->new--->import project当前解压sdk路径,使用在线服务能力选择导入SpeechDemo,如下图所示: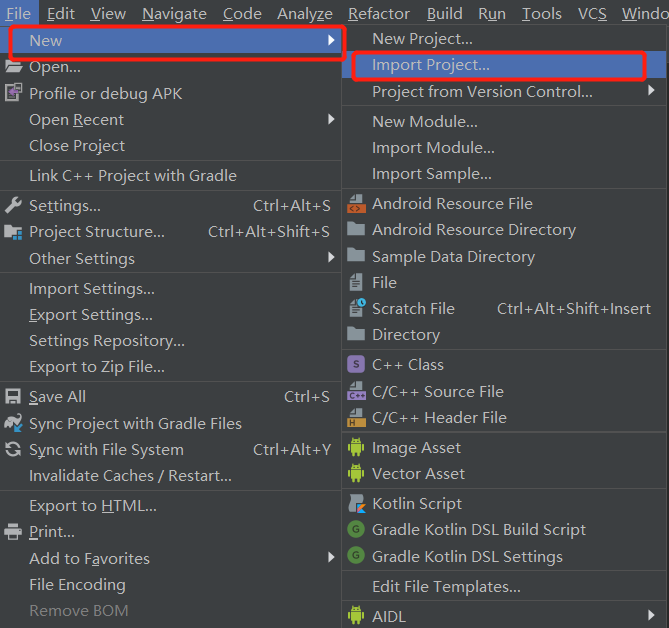
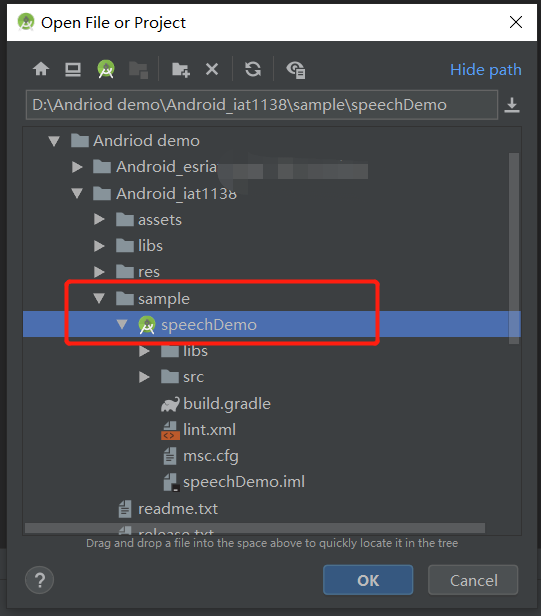
导入成功之后sync编译下,编译无误可连接手机,开启手机USB开发调试模式,直接在Android Studio运行导入的Speechdemo,最后生成的apk可直接安装在对应的手机上,如下图所示: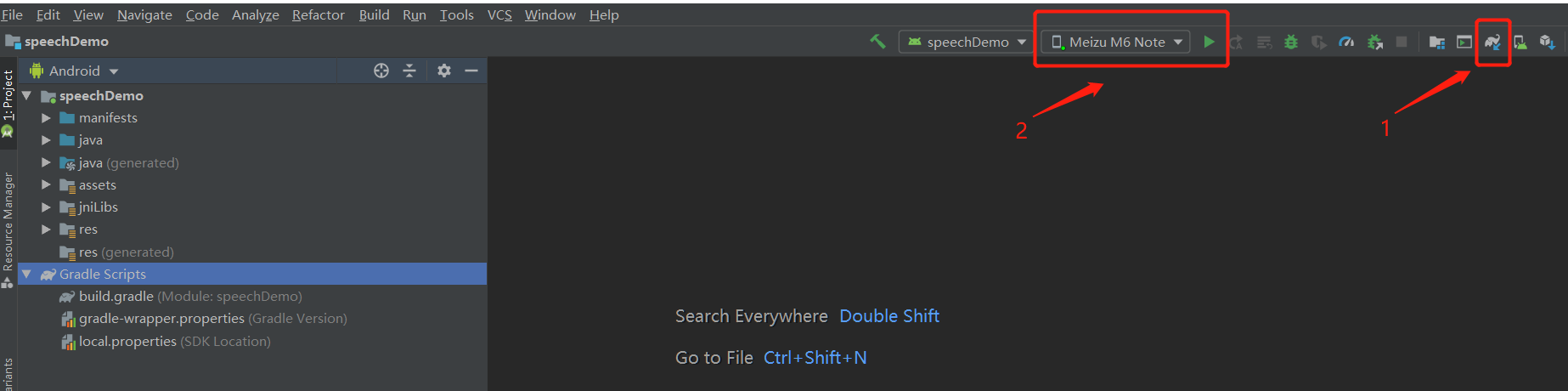
如果编译时出现“ERROR: Plugin with id 'com.android.application' not found.”错误,请在build.gradle文件中添加以下代码。
buildscript {
repositories {
google()
jcenter()
}
dependencies {
//版本号请根据自己的gradle插件版本号自行更改
classpath 'com.android.tools.build:gradle:3.4.0'
// NOTE: Do not place your application dependencies here; they belong
// in the individual module build.gradle files
}
}
如在导入项目中还出现其他问题,可参考帖子:安卓demo常见错误排查
#方法二(导入module方式):
打开Android Studio,在菜单栏File--->new--->import module当前解压sdk路径,使用在线服务能力选择导入SpeechDemo。 导入成功之后sync编译下,编译无误可连接手机,开启手机USB开发调试模式,直接在Android Studio运行导入的Speechdemo,最后生成的apk可直接安装在对应的手机上。
#2.2、项目集成步骤
#2.2.1、SDK包说明
《Android SDK目录结构一览》
- manifests:
- android配置应用权限文件
- sample:
- 相关在线能力demo(语音听写IatDemo)
- assets:
- SDK相关资源配置文件
- Libs:
- 动态库和jar包
- res:
- UI文件和相关布局文件xml
- readme说明(必看)
- release 版本说明
#2.2.2、导入SDK
将在官网下载的Android SDK 压缩包中libs目录下所有子文件拷贝至Android工程的libs目录下。如下图所示:
注:
- arm版本已经逐步淘汰了,arm架构的推荐使用armeabi-v7a。
- 如果您需要将应用push到设备使用,请将设备cpu对应指令集的libmsc.so push到/system/lib中。
- 集成到项目,需要将sdk中Demo/src/main/下文件拷贝到项目main中,以AS为例,且需要在项目main文件夹下新建Jnilibs并拷贝libmsc.so
- msc.jar需要拷贝至项目libs下,并且右键jar添加Add As Library。
- sdk下文件夹main/assets/,自带UI页面(iflytek文件夹)和相关其他服务资源文件(语法文件、音频示例、词表),使用自带UI接口时,可以将assets/iflytek文件拷贝到项目中;
#2.2.3、添加用户权限
在工程 AndroidManifest.xml 文件中添加如下权限
<!--连接网络权限,用于执行云端语音能力 -->
<uses-permission android:name="android.permission.INTERNET"/>
<!--获取手机录音机使用权限,听写、识别、语义理解需要用到此权限 -->
<uses-permission android:name="android.permission.RECORD_AUDIO"/>
<!--读取网络信息状态 -->
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE"/>
<!--获取当前wifi状态 -->
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE"/>
<!--允许程序改变网络连接状态 -->
<uses-permission android:name="android.permission.CHANGE_NETWORK_STATE"/>
<!--读取手机信息权限 -->
<uses-permission android:name="android.permission.READ_PHONE_STATE"/>
<!--读取联系人权限,上传联系人需要用到此权限 -->
<uses-permission android:name="android.permission.READ_CONTACTS"/>
<!--外存储写权限,构建语法需要用到此权限 -->
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE"/>
<!--外存储读权限,构建语法需要用到此权限 -->
<uses-permission android:name="android.permission.READ_EXTERNAL_STORAGE"/>
<!--配置权限,用来记录应用配置信息 -->
<uses-permission android:name="android.permission.WRITE_SETTINGS"/>
<!--手机定位信息,用来为语义等功能提供定位,提供更精准的服务-->
<!--定位信息是敏感信息,可通过Setting.setLocationEnable(false)关闭定位请求 -->
<uses-permission android:name="android.permission.ACCESS_FINE_LOCATION"/>
<!--如需使用人脸识别,还要添加:摄像头权限,拍照需要用到 -->
<uses-permission android:name="android.permission.CAMERA" />
注意:如需在打包或者生成APK的时候进行混淆,请在proguard.cfg中添加如下代码:
-keep class com.iflytek.**{*;}
-keepattributes Signature
#2.2.4、初始化
初始化即创建语音配置对象,只有初始化后才可以使用MSC的各项服务。建议将初始化放在程序入口处(如Application、Activity的onCreate方法),初始化代码如下:
// 将“12345678”替换成您申请的APPID,申请地址:http://www.xfyun.cn
// 请勿在“=”与appid之间添加任何空字符或者转义符
SpeechUtility.createUtility(context, SpeechConstant.APPID +"=12345678");
#2.2.5、常用参数说明
| 参数名称 | 名称 | 说明 |
|---|---|---|
| domain | 应用领域 | 应用领域 iat:日常用语 medical:医疗 注:医疗领域若未授权无法使用,可到控制台-语音听写(流式版)-高级功能处添加试用或购买;若未授权无法使用会报错11200。 |
| language | 语言区域 | 选择要使用的语言区域,目前Android SDK支持 zh_cn:中文 en_us:英文 ja_jp:日语 ko_kr:韩语 ru-ru:俄语 fr_fr:法语 es_es:西班牙语 注:小语种若未授权无法使用会报错11200,可到控制台-语音听写(流式版)-方言/语种处添加试用或购买。 |
| accent | 方言 | 当前仅在LANGUAGE为简体中文时,支持方言选择,其他语言区域时,可把此参数值设为mandarin。默认值:mandarin,其他方言参数可在控制台方言一栏查看。 |
| vad_bos | 前端点检测 | 开始录入音频后,音频前面部分最长静音时长,取值范围[0,10000ms],默认值5000ms |
| vad_eos | 后端点检测 | 开始录入音频后,音频后面部分最长静音时长,取值范围[0,10000ms],默认值1800ms。 |
| sample_rate | 采样率 | 支持:8KHz(仅在线支持),16KHz |
| nbest | 句子多候选 | 通过设置此参数,获取在发音相似时的句子多候选结果。设置多候选会影响性能,响应时间延迟200ms左右。取值范围:听写[1,5]。 注:该扩展功能若未授权无法使用,可到控制台-语音听写(流式版)-高级功能处免费开通;若未授权状态下设置该参数并不会报错,但不会生效。 |
| wbest | 词语多候选 | 通过设置此参数,获取在发音相似时的词语多候选结 果。设置多候选会影响性能,响应时间延迟200ms左右。取值范围:听写[1,5]。 注:该扩展功能若未授权无法使用,可到控制台-语音听写(流式版)-高级功能处免费开通;若未授权状态下设置该参数并不会报错,但不会生效。 |
| result_type | 结果类型 | 结果类型包括:xml, json, plain。xml和json即对应的结构化文本结构,plain即自然语言的文本。 |
| nunum | 数字结果 | 通过设置此参数可偏向输出数字结果格式 0:倾向于汉字, 1:倾向于数字, 设置方式:mIat.setParameter("nunum", "0") |
| ptt | 标点符号 | (仅中文支持)标点符号添加 1:开启(默认值) 0:关闭 |
注: 多候选效果是由引擎决定的,并非绝对的。即使设置了多候选,如果引擎并没有识别出候选的词或句,返回结果也还是单个。
备注:以上均为SDK常用参数说明,均在setParam()方法里面设置,设置示例:mIat.setParameter(SpeechConstant.LANGUAGE, "en_us");更多详细参数请参考:MSC Android API 文档 .
#2.2.6、在线听写UI设置
sdk提供了两种识别方式,分别为带UI识别和无UI方式:
#2.2.6.1、无UI识别
//初始化识别无UI识别对象
//使用SpeechRecognizer对象,可根据回调消息自定义界面;
mIat = SpeechRecognizer.createRecognizer(IatDemo.this, mInitListener);
//设置语法ID和 SUBJECT 为空,以免因之前有语法调用而设置了此参数;或直接清空所有参数,具体可参考 DEMO 的示例。
mIat.setParameter( SpeechConstant.CLOUD_GRAMMAR, null );
mIat.setParameter( SpeechConstant.SUBJECT, null );
//设置返回结果格式,目前支持json,xml以及plain 三种格式,其中plain为纯听写文本内容
mIat.setParameter(SpeechConstant.RESULT_TYPE, "json");
//此处engineType为“cloud”
mIat.setParameter( SpeechConstant.ENGINE_TYPE, engineType );
//设置语音输入语言,zh_cn为简体中文
mIat.setParameter(SpeechConstant.LANGUAGE, "zh_cn");
//设置结果返回语言
mIat.setParameter(SpeechConstant.ACCENT, "mandarin");
// 设置语音前端点:静音超时时间,单位ms,即用户多长时间不说话则当做超时处理
//取值范围{1000~10000}
mIat.setParameter(SpeechConstant.VAD_BOS, "4000");
//设置语音后端点:后端点静音检测时间,单位ms,即用户停止说话多长时间内即认为不再输入,
//自动停止录音,范围{0~10000}
mIat.setParameter(SpeechConstant.VAD_EOS, "1000");
//设置标点符号,设置为"0"返回结果无标点,设置为"1"返回结果有标点
mIat.setParameter(SpeechConstant.ASR_PTT,"1");
//开始识别,并设置监听器
mIat.startListening(mRecogListener);
#2.2.6.2、带UI识别
// 初始化听写Dialog,如果只使用有UI听写功能,无需创建SpeechRecognizer
// 使用UI听写功能,请根据sdk文件目录下的notice.txt,放置布局文件和图片资源
mIatDialog = new RecognizerDialog(IatDemo.this, mInitListener);
//以下为dialog设置听写参数
mIatDialog.setParams("xxx","xxx");
....
//开始识别并设置监听器
mIatDialog.setListener(mRecognizerDialogListener);
//显示听写对话框
mIatDialog.show();
#2.3、个性化热词设置
无论在哪一种语言中,不同的单词或字(word),或多或少,都会有相似的发音(pronounce)。尤其在汉语中,这种现象更普遍,如当一个人说 /zhang/ /s[h]an/ 时,对应的词语的组成,可能是 {张,章,彰,...} {三,姗,珊,...},这些文字的组合,在汉语的习惯中出现频率最高的,当然是“张三”了。
而在听写返回结果时,会结合上下文,把日常生活中,出现频率最高的词汇返回给客户端。这时,如果我们实际想要的结果并不是出现频率最高的词汇,如上文中我们实际要的是“张姗”——这样的情况在手机联系人信息中经常会出现,此时听写结果就不是我们想要的。这种情况下,我们可以通过上传个性化热词的方式,增加热词的识别权重,需要注意的这些个性化信息只是增加相应词条的识别率,但并不是绝对的。
个性化热词分为:应用级热词和用户级热词。
用户级热词:在程序代码中上传的叫用户级热词(参考MSC Android API 文档中 SpeechRecognizer 类的 updateLexicon 函数介绍,demo里面也有代码示例),用户级热词只对上传热词的某个用户(设备)生效,一般上传后10分钟左右生效,影响的范围是,当前 APPID 应用的当前设备——即同一应用,不同设备里上传的热词互不干扰;同一设备,不同APPID的应用上传的热词互不干扰。
应用级热词:在网页上上传的是应用级热词(讯飞开放平台官网—控制台 —个性化热词设置),上传后1-2小时后生效,应用级热词是对所有运行你应用的设备都生效,更新给当前APPID的所有使用设备。
mAsr.setParameter( SpeechConstant.ENGINE_TYPE, SpeechConstant.TYPE_CLOUD );
// lexiconName 为词典名字,lexiconContents 为词典内容,lexiconListener 为回调监听器
ret = mAsr.updateLexicon( lexiconName, lexiconContents, lexiconListener );
注:个性化热词仅支持中文,不支持数字和英文及其他小语种。
#2.4、代理服务器设置方法
在createUtility接口的params参数中添加:
net_type=custom, proxy_ip=<host>, proxy_port=<port>
其中,<host>,<port>替换为实际的代理服务器地址和端口。
例如:SpeechUtility.createUtility(context, SpeechConstant.APPID + “=12345678” + “,” + “net_type=custom, proxy_ip=192.168.1.2, proxy_port=8080”); 注意:各参数间,以英文逗号分隔。
接口原型: public static SpeechUtility createUtility(Context context, java.lang.String params)
注意: 若在设置代理参数后,使用语音服务过程中,报错10204/10205/10212等网络异常错误时,请查阅以下内容,做出相关操作:
- 讯飞语音SDK的通信协议使用的是标准HTTP1.1协议,其代理协议使用的是标准HTTP代理协议。
- 代理服务器需要支持全双工多问多答方式,即 pipeline 模式。
- 代理服务器不能对80端口做限制,不能对如下域名做拦截: hdns.openspeech.cn scs.openspeech.cn open.xf-yun.com dev.voicecloud.cn
- 需要确保代理服务器只负责转发数据包,不能改变数据包的完整性和时序性。
- 代理服务器在转发数据包时,不能在HTTP协议头部添加 IE6 标识头。
#3、参数说明
#3.1、识别结果
| JSON字段 | 英文全称 | 类型 | 说明 |
|---|---|---|---|
| sn | sentence | number | 第几句 |
| ls | last sentence | boolean | 是否最后一句 |
| bg | begin | number | 保留字段,无需关注 |
| ed | end | number | 保留字段,无需关注 |
| ws | words | array | 词 |
| cw | chinese word | array | 中文分词 |
| w | word | string | 单字 |
| sc | score | number | 分数 |
听写结果示例:
{
"sn": 1,
"ls": true,
"bg": 0,
"ed": 0,
"ws": [
{
"bg": 0,
"cw": [
{
"w": "今天",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": "的",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": "天气",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": "怎么样",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": "。",
"sc": 0
}
]
}
]
}
多候选结果示例:
{
"sn": 1,
"ls": false,
"bg": 0,
"ed": 0,
"ws": [
{
"bg": 0,
"cw": [
{
"w": "我想听",
"sc": 0
}
]
},
{
"bg": 0,
"cw": [
{
"w": "拉德斯基进行曲",
"sc": 0
},
{
"w": "拉得斯进行曲",
"sc": 0
}
]
}
]
}
#3.2、动态修正
- 未开启动态修正:实时返回识别结果,每次返回的结果都是对之前结果的追加;
- 开启动态修正:实时返回识别结果,每次返回的结果有可能是对之前结果的的追加,也有可能是要替换之前某次返回的结果(即修正);
- 开启动态修正,相较于未开启,返回结果的颗粒度更小,视觉冲击效果更佳;
- 使用动态修正功能需到控制台-流式听写-高级功能处点击开通,并设置相应参数方可使用,参数设置方法:mIat.setParameter("dwa", "wpgs"); ;
- 动态修正功能仅 中文 支持;
- 未开启与开启返回的结果格式不同,详见下方;
若开通了动态修正功能并设置了dwa=wpgs(仅中文支持),会有如下字段返回:
| 参数 | 类型 | 描述 |
|---|---|---|
| pgs | string | 开启wpgs会有此字段 取值为 "apd"时表示该片结果是追加到前面的最终结果;取值为"rpl" 时表示替换前面的部分结果,替换范围为rg字段 |
| rg | array | 替换范围,开启wpgs会有此字段 假设值为[2,5],则代表要替换的是第2次到第5次返回的结果 |
动态修正返回结果解析代码示例:
// 读取动态修正返回结果示例代码
private void printResult(RecognizerResult results) {
String text = JsonParser.parseIatResult(results.getResultString());
String sn = null;
String pgs = null;
String rg = null;
// 读取json结果中的sn字段
try {
JSONObject resultJson = new JSONObject(results.getResultString());
sn = resultJson.optString("sn");
pgs = resultJson.optString("pgs");
rg = resultJson.optString("rg");
} catch (JSONException e) {
e.printStackTrace();
}
//如果pgs是rpl就在已有的结果中删除掉要覆盖的sn部分
if (pgs.equals("rpl")) {
String[] strings = rg.replace("[", "").replace("]", "").split(",");
int begin = Integer.parseInt(strings[0]);
int end = Integer.parseInt(strings[1]);
for (int i = begin; i <= end; i++) {
mIatResults.remove(i+"");
}
}
mIatResults.put(sn, text);
StringBuffer resultBuffer = new StringBuffer();
for (String key : mIatResults.keySet()) {
resultBuffer.append(mIatResults.get(key));
}
mResultText.setText(resultBuffer.toString());
mResultText.setSelection(mResultText.length());
}
返回结果示例: "rpl":替换 示例
{
"sn": 2,
"ls": false,
"bg": 0,
"ed": 0,
"pgs": "rpl",
"rg": [
1,
1
],
"ws": [
{
"bg": 0,
"cw": [
{
"sc": 0.00,
"w": "我"
}
]
},
{
"bg": 0,
"cw": [
{
"sc": 0.00,
"w": "的"
}
]
},
{
"bg": 0,
"cw": [
{
"sc": 0.00,
"w": "两"
}
]
},
{
"bg": 0,
"cw": [
{
"sc": 0.00,
"w": "个"
}
]
},
{
"bg": 0,
"cw": [
{
"sc": 0.00,
"w": "短信"
}
]
}
]
}
"apd":追加 示例
{
"sn": 3,
"ls": false,
"bg": 0,
"ed": 0,
"pgs": "apd",
"ws": [
{
"bg": 0,
"cw": [
{
"sc": 0.00,
"w": ","
}
]
},
{
"bg": 0,
"cw": [
{
"sc": 0.00,
"w": "昨天"
}
]
},
{
"bg": 0,
"cw": [
{
"sc": 0.00,
"w": "晚上"
}
]
}
]
}
#4、视频教程
#5、常见问题
#目前安卓平台具体支持安卓版本
答:Android版本SDK目前支持4.4以上版本,React-Native ,QT 等跨平台方案,目前暂不支持
#集成语音识别功能时,程序启动后没反应
答:请检查是否忘记使用SpeechUtility初始化。也可以在监听器的onError函数中打印错误信息,根据信息提示,查找错误源。
#SDK是否支持本地语音能力?
答:Android平台SDK已经支持本地合成、本地命令词识别、本地语音唤醒功能了,创建应用后前往应用控制台下载各服务sdk即可。
#获取到语音听写结果为空或错误内容或者内容不全的原因是什么?
答:原因可能是:
1、音频格式不正确,客户端支持的音频编解码算法只支持16位Intel PCM格式的音频,请使用Cool Edit Pro工具(网页搜索下载即可)查看音频格式,sdk目前支持的格式是 pcm 和 wav 格式、音频采样率要是 16k 或者 8k、采样精度16 位、单声道音频。
2、引擎的参数设置不正确,如没有设置好正确的引擎类型和采样率等。
3、音频中间有静音或者杂音音频超过了后端点(默认为1800ms)的设置,此时请使用Cool Edit Pro工具查看音频内容,并且设置后端点(vad_eos)为最大值10000ms
包含超过后端点最大值的静音或者杂音音频识别不完整是正常的。
#错误码21001, 21002, 20021, 创建单例返回 null
答:参考以下帖子:http://bbs.xfyun.cn/forum.php?mod=viewthread&tid=9688
#如何设置识别业务所需的额外参数(其它业务类似)?
答:如要设置参数对:abc = 123,则应写:mIat.setParameter("abc", "123"); 各类参数设置参考安卓api文档
#如何设置语音云服务URL?
答:在createUtility接口中添加:server_url = http://YourDomainName/msp.do (YourDomainName是指语音云服务域名,请开发者自行替换) 例如:SpeechUtility.createUtility(context, SpeechConstant.APPID + "=12345678" + "," + "server_url = http://sdk.openspeech.cn/msp.do");
注意:各参数间,以英文逗号分隔。 接口原型: public static SpeechUtility createUtility(Context context, java.lang.String params)
#SDK形式是否支持多路并发?
答:sdk:客户端解决方案,支持Android、ios、windows、linux等平台,不支持并发; webapi:服务端解决方案,不限制平台、不限制语言,支持并发。
#语音听写支持识别多长时间的音频,支持的音频格式是什么?
答:语音听写的功能是可以识别60S以内的短音频,将音频转化成文本信息。
听写sdk目前支持的格式是 pcm 和 wav 格式、音频采样率要是 16k 或者 8k、采样精度16 位、单声道音频。请使用cool edit软件(网页搜索下载此软件即可)查看音频格式是否满足相应的识别引擎类型,否则识别为空或者识别为错误文本,格式必须正确,除上述格式均不识别,音频格式一定要满足要求。现语音听写WebAPI接口的中文普通话和英文支持mp3格式,如有需要,请参考语音听写(流式版)WebAPI
具体可以参考:http://bbs.xfyun.cn/forum.php?mod=viewthread&tid=7051
另外我们识别的音频长度最大为 60S,在使用音频是要注意你的本地音频的参数要和代码里的读取音频参数保持一致
#安卓听写sdk如何下载?
答:文档中心---快速指引 有介绍步骤---根据步骤下载安卓在线听写sdk
#听写识别结果如何显示阿拉伯数字?
答:设置nunum=1即可优先返回阿拉伯数字。
#为什么使用音频文件返回结果为空、音频文件识别不完整?
答:音频格式不正确或者音频格式与设置的参数不匹配。
#为什么保存的本地录音无法播放?
答:保存的音频格式为pcm格式的音频,是无法直接播放的,可下载下来使用cool edit pro进行播放。
#听写会识别手机发出的声音,如何屏蔽手机声音?
答:设置mIse.setParameter("KEY_REQUEST_FOCUS", "true");即可暂停手机声音。
#如何设置返回结果不打印标点符号?
答:ASR_PTT表示是否返回标点符号,通过此参数,设置听写文本结果是否含标点符号。0表示不带标点,1则表示带标点。
#最多支持多少热词,是否可以扩容?
答:控制台最多支持2000个热词,暂不支持扩容。
#是否支持x86架构?
答:目前不支持x86架构。