Windows SDK接入文档
注意: 该接口可以正式使用。如您需要申请使用,请点击前往产品页面 。
Tips:
- 计费包含接口的输入和输出内容
- 1tokens 约等于1.5个中文汉字 或者 0.8个英文单词
- 星火V1.5支持[搜索]内置插件;星火V2.0和V3.0支持[搜索]、[天气]、[日期]、[诗词]、[字词]、[股票]六个内置插件
#1. SDK介绍
Spark SDK提供了一套快速集成星火大模型的工具,让开发者无需关注底层协议细节,提高开发效率。支持Android、Linux、iOS、Windows多个平台,方便开发者选择最适合自己的平台进行开发。Spark SDK可以帮助企业快速将星火大模型应用到业务场景中,提高效率和竞争力。本文档主要介绍Windows平台集成过程。
#2. 兼容性说明
| 类别 | 兼容范围 |
|---|---|
| 系统 | 支持Windows x64和Windows x86,支持Win7、Win10主流Windows平台 |
| 开发环境 | 建议使用 Visual Studio 进行开发 |
#3. 授权说明
星火认知大模型授权支持按照tokens授权和设备级授权两种方式。
tokens 授权:授权tokens总量,按照tokens 使用量计费,1 tokens 约等于1.5个中文汉字 或者 0.8个英文单词。
设备级授权:授权设备台数和有效期,按照设备指纹计量计费,此方式仅支持定制级客户,如有需要请与开放平台联系。
#4. SDK集成包目录结构
将SDK zip包解压缩,得到如下文件:
├── Demo Spark的使用DEMO,DEMO中已经集成了SDK,您可以参考DEMO,集成SDK。集成前,请先测通DEMO,了解调用原理。
├── ReleaseNotes.txt SDK版本日志
├── SDK Spark SDK
│ └── SparkChain.dll
│ └── SparkChain.lib
└── SparkChain LLM Windows SDK集成文档.pdf Spark集成指南
#5. 接口调用流程图
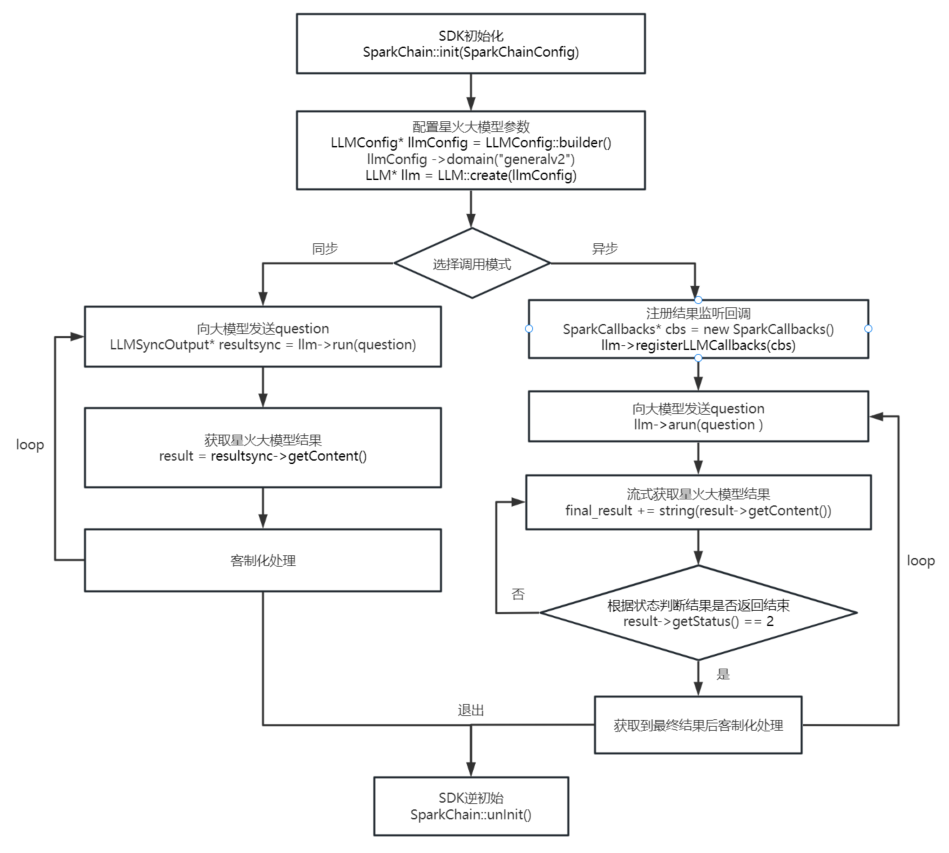
#6. SDK工程配置
#6.1 导入SDK库
将SDK/libs文件夹、头文件文件夹include存放到项目中,并在环境变量里添加库路径;
#include "../include/sparkchain.h"
#6.2 配置权限
如果需要存储日志,SDK日志路径需要读写权限,缺少读写权限,日志将无法正常存储。
#7. 快速集成
#7.1 SDK初始化
在使用Spark SDK 星火大模型交互功能前,需要首先开通星火大模型授权并获取已开通授权的应用信息(appId、apiKey、apiSecret)。SDK全局只需要初始化一次。初始化示例如下:
SparkChainConfig* config = SparkChainConfig::builder();
//配置应用信息
config->appID("$appId")
->apiKey("$apiKey")
->apiSecret("$apiSecret");
int ret = SparkChain::init(config);
初始化参数说明:
| 参数名 | 类型 | 说明 | 是否必填 |
|---|---|---|---|
| appID | char* | 创建应用后,生成的应用ID | 是 |
| apiKey | char* | 创建应用后,生成的唯一应用标识 | 是 |
| apiSecret | char* | 创建应用后,生成的唯一应用秘钥 | 是 |
| logLevel | int | 0:VERBOSE,1:DEBUG,2:INFO,3:WARN,4:ERROR,5:FATAL,100:OFF | 否 |
| logPath | char* | 日志存储路径,设置则会把日志存在该路径下,不设置则会把日志打印在终端上 | 否 |
| uid | char* | 用户自定义标识 | 否 |
初始化返回值:0:初始化成功,非0:初始化失败,请根据具体返回值参考错误码章节查询原因。
#7.2 配置星火大模型参数
首先需要配置星火大模型的相关参数,示例如下:
LLMConfig* llmConfig = LLMConfig::builder();
llmConfig ->domain("generalv2");
llmConfig ->url("ws(s)://spark-api.xf-yun.com/v2.1/chat");//如果使用generalv2,domain和url都可缺省,SDK默认;如果使用general,url可缺省,SDK会自动补充;如果是其他,则需要设置domain和url。
LLM* llm = LLM::create(llmConfig);
参数说明:
| 字段 | 含义 | 类型 | 限制 | 是否必传 |
|---|---|---|---|---|
| domain | 需要使用的领域 | char* | 取值为[general,generalv2],默认generalv2 general:通用大模型V1.5版本 generalv2:通用大模型V2版本 general和generalv2对应的url不同,需要严格对应。url地址参见下文。 | 否 |
| url | 配置chat服务器域名地址 | char* | general:ws(s): //spark-api.xf-yun.com/v1.1/chat generalv2:ws(s): //spark-api.xf-yun.com/v2.1/chat generalv3:ws(s): //spark-api.xf-yun.com/v3.1/chat domian 取值为 general或generalv2 时,SDK自动设置url,可缺省。 | 否 |
| maxToken | 回答的tokens的最大长度 | int | 取值范围1-4096,默认2048 | 否 |
| temperature | 配置核采样阈值,改变结果的随机程度 | float | 最小是0, 最大是1,默认0.5 | 否 |
| auditing | 内容审核的场景策略 | char* | 当前仅支持default | 否 |
| topK | 配置从k个候选中随机选择⼀个(⾮等概率) | int | 取值范围1-6,默认值4 | 否 |
| chatID | 配置关联会话chat_id标识,需要保障用户下唯一 | char* | 否 |
#7.3 星火请求调用
当前支持同步调用和异步调用两种方式。用户可以通过run方法或者arun方法向大模型发送问题请求,获取大模型返回结果。run方法、arun方法不支持并发调用。
#7.3.1 同步调用
#7.3.1.1 请求调用
调用 run方法向大模型发起请求,并同步一次性返回大模型回答结果。该接口返回结果延迟时间取决于大模型返回的结果长度。
// llm 同步接口
LLMSyncOutput* result = llm->run("给我讲个笑话吧。");
if (result->getErrCode() != 0)
printf(RED "\nsyncOutput: %d:%s\n\n" RESET, result->getErrCode(), result->getErrMsg());
else
printf(GREEN "\nsyncOutput: %s:%s tokens:%d + %d = %d\n\n" RESET, result->getRole(), result->getContent());
run方法参数说明:
| 参数名 | 类型 | 说明 | 限制 | 是否必填 |
|---|---|---|---|---|
| question | char* | 输入信息文本 | general:4096 tokens generalv2:8192 tokens | 是 |
LLMSyncOutput数据结构说明:
| 参数 | 类型 | 获取方法 | 说明 |
|---|---|---|---|
| errCode | int | getErrCode() | 调用结果状态,0:调用成功,非0:调用失败 |
| errMsg | char* | getErrMsg() | 调用失败时的错误信息 |
| role | char* | getRole() | 星火大模型的角色,assistant::助手,user:用户 |
| content | char* | getContent() | 调用结果 |
| completionTokens | int | getCompletionTokens() | 回答的Token大小 |
| promptTokens | int | getPromptTokens() | 包含历史问题的总Tokens大小 |
| totalTokens | int | getTotalTokens() | promptTokens和completionTokens的和,也是本次交互计费的Tokens大小 |
返回结果参考7.5节响应协议说明。
#7.3.2 异步调用
调用 arun方法向大模型发起请求,通过LLMCallbacks 接口回调的方式异步返回大模型回答结果。可在回调接口中接收异步返回的数据和数据和状态。
#7.3.2.1.注册结果回调
class SparkCallbacks : public LLMCallbacks {
void onLLMResult(LLMResult* result, void* usrContext) {
int status = result->getStatus();
printf(GREEN "%d:%s:%s " "usrContext:%d\n" RESET, status, result->getRole(), result->getContent(), *(int*)usrContext);
if (status == 2) {
//结果返回已完成
}
}
void onLLMEvent(LLMEvent* event, void* usrContext) {
printf(YELLOW "onLLMEventCB\n eventID:%d eventMsg:%s " "usrContext:%d\n" RESET, event->getEventID(), event->getEventMsg(), *(int*)usrContext);
}
void onLLMError(LLMError* error, void* usrContext) {
printf(RED "onLLMErrorCB\n errCode:%d errMsg:%s " "usrContext:%d\n" RESET, error->getErrCode(), error->getErrMsg(), *(int*)usrContext);
}
};
// llm 异步接口
SparkCallbacks* cbs = new SparkCallbacks(); // 创建回调
llm->registerLLMCallbacks(cbs); // 注册回调
LLMCallbacks数据结构说明:
- onLLMResult为星火请求结果回调,参数说明如下:
| 参数 | 类型 | 说明 |
|---|---|---|
| result | LLMResult* | 星火大模型结果实例 |
| usrContext | void* | 用户自定义标识 |
- LLMResult结构说明:
| 方法 | 说明 |
|---|---|
| getRole() | 星火大模型角色,assistant::助手,user:用户 |
| getContent() | 调用结果 |
| getCompletionTokens() | 回答的Token大小 |
| getPromptTokens() | 包含历史问题的总Tokens大小 |
| getTotalTokens() | promptTokens和completionTokens的和,也是本次交互计费的Tokens大小 |
| getStatus() | 返回结果状态,0:start,1:continue,2:end |
- onLLMEvent为星火请求事件回调,参数说明如下:
| 参数 | 类型 | 说明 |
|---|---|---|
| event | LLMEvent* | 调用事件结果实例 |
| usrContext | void* | 用户自定义标识 |
- LLMEvent结构说明:
| 方法 | 说明 |
|---|---|
| getEventID() | 事件ID,15:建立连接,19:连接断开 |
| getEventMsg() | 事件信息 |
- onLLMError为星火请求错误回调,参数说明如下:
| 参数 | 类型 | 说明 |
|---|---|---|
| error | onLLMError* | 错误信息结果实例 |
| usrContext | void* | 用户自定义标识 |
- LLMError结构说明:
| 方法 | 说明 |
|---|---|
| getErrCode() | 错误码ID |
| getErrMsg() | 错误信息 |
#7.3.2.2 请求调用
int usrContext = 1;//
ret = llm->arun("给我讲个笑话吧。", &usrContext);
arun方法参数说明:
| 参数 | 类型 | 说明 | 限制 | 是否必填 |
|---|---|---|---|---|
| question | char* | 输入信息文本 | general:4096 tokens generalv2:8192 tokens | 是 |
| usrTag | void* | 用户自定义标识 | 否 |
返回结果参考7.5节响应协议说明。
#7.4 多轮会话
如果交互需要上下文关联,需要把交互历史数据一并传入到run方法或者arun方法中。传入格式如下:
[
{"role":"user","content":"上海有什么景点?"},// ⽤户第⼀个问题 role是user,表示是⽤户的提问
{"role":"assistant","content":"上海有很多著名的景点,其中排名前十的是:\n\n1. 上海迪士尼乐园\n2. 上海静安寺\n3. 南翔古镇"},// AI的第⼀个回复 role是assistant,表示是AI的回复
{"role":"user","content":"那帮我安排一份旅游计划吧。"}// ⽤户第⼆个问题
]
开发者需要构建如上格式的JsonArray字符串传入run或者arun方法中。
#7.5 响应协议说明
该协议为中间协议,星火大模型是按照此协议格式返回结果。SDK已完成对此协议的解析和封装,获取相应字段方法请查询7.3节LLMOutput和LLMResult的结构说明。
# 接口为流式返回,此示例为最后一次返回结果,开发者需要将接口多次返回的结果进行拼接展示
{
"header":{
"code":0,
"message":"Success",
"sid":"cht000b2d3c@dx18a980cc0beb894540",
"status":2
},
"payload":{
"choices":{
"status":2,
"seq":9,
"text":[
{
"content":"”",
"role":"assistant",
"index":0
}
]
},
"usage":{
"text":{
"question_tokens":15,
"prompt_tokens":15,
"completion_tokens":61,
"total_tokens":76
}
}
}
}
协议结构说明
| 字段 | 含义 | 说明 |
|---|---|---|
| header | 协议头部 | 协议头部,用于描述平台特性的参数 |
| payload | 响应数据块 | 数据段,携带响应的数据。 |
响应参数说明
| 字段 | 含义 |
|---|---|
| sid | 本次会话的id |
| status | 数据状态 0:start,1:continue,2:end |
| seq | 数据序号,标明数据为第几块。最小值:0, 最大值:9999999 |
| content | 文本数据 |
| role | 星火大模型角色 |
| prompt_tokens | 包含历史问题的总Tokens大小 |
| completion_tokens | 回答的Token大小 |
| total_tokens | promptTokens和completionTokens的和,也是本次交互计费的Tokens大小 |
7.6 SDK逆初始化
当SDK需要完整退出时,需调用逆初始化方法释放资源,示例代码如下:
SparkChain::unInit();
#8. 错误码
错误码包含SDK错误码和云端错误码,SDK错误码用来反馈SDK本地运行时遇到的错误;云端错误码用来反馈星火大模型交互时服务端错误。
#8.1 SDK错误码
| 错误码 | 含义 | 自查指南 |
|---|---|---|
| 0 | 操作成功 | |
| 18007 | 授权应用不匹配(apiKey、apiSecret) | apiKey、apiSecret 配置有误,请核对项目中配置的 apiKey、apiSecret 。 |
| 18301 | SDK未初始化 | 在使用大模型前请先初始化 SDK,如果有调用 uninit 方法,再次使用大模型交互时需要重新初始化。 |
| 18302 | SDK初始化失败 | 请根据init接口回调中返回的错误码参考此文档做对应检查 |
| 18303 | SDK 已经初始化 | 重复初始化导致,使用能力时,SDK 只需要初始化一次,请检查 SDK 初始化逻辑是否存在多次初始化。 |
| 18304 | 不合法参数 | 请参考demo及集成文档仔细检查所传参数是否正确。 |
| 18311 | sdk同一能力并发路数超出最大限制 | |
| 18312 | 此实例已处在运行态,禁止单实例并发运行 | |
| 18400 | 工作目录无写权限 | 在设置 workDir 时,请确保该工作路径有读写权限。若无法设置读写权限,请修改为有读写权限的工作路径。 |
| 18402 | 文件打开失败 | 请检查 日志中所打印的文件是否存在,以及对应路径下是否有读权限。 |
| 18500 | 未找到该参数 key | 请参照demo或集成文档仔细检查参数名拼写 |
| 18501 | 参数范围溢出,不满足约束条件 | 请根据文档检查调用 SDK 方法时所传参数范围,需要确保所传参数符合协议约束要求 |
| 18502 | SDK 初始化参数为空 | 请根据 SDK 集成文档检查 SDK 初始化代码,确保必填参数有值且合法 |
| 18503 | SDK 初始化参数中 appId 为空 | appId 为空值,请在 SDK 初始化时传入正确的 appId 值 |
| 18504 | SDK 初始化参数中 apiKey为空 | apiKey为空值,请在 SDK 初始化时传入正确的 apiKey值 |
| 18505 | SDK 初始化参数中 apiSecret 为空 | apiSecret 为空值,请在 SDK 初始化时传入正确的 apapiSecret 值 |
| 18509 | 必填参数缺失 | 请参考demo或者文档检查是否漏传必填参数 |
| 18700 | 通用网络错误 | 请检查网络连接是否正常 |
| 18701 | 网络不通 | 请检查网络连接是否正常 |
| 18702 | 网关检查不过 | 检查设备时间是否正确; 请检查 SDK 初始化时所传 apiKey、apiScrect 是否正确; |
| 18703 | 云端响应格式不对 | 请检查网络是否可以正常访问外网 |
| 18705 | 应用 ApiKey & ApiSecret 校验失败 | 请检查 apiKey、apiSecret 是否正确 |
| 18707 | 授权已过期 | 请检查授权期限 |
| 18708 | 无可用授权 | 没有授权或者授权已满 |
| 18712 | 网络请求 404 错误 | 请检查网络是否通畅 |
| 18713 | 设备指纹安全等级不匹配 | 设备指纹安全等级不符合要求 |
| 18714 | 应用信息有误 | 服务端无法查询到api_key,请检查api_key和api_secret信息是否填写正确 |
| 18717 | SDK授权不足 | 授权数量已满 |
| 18801 | 连接建立出错 | 请检查网络是否通畅 |
| 18802 | 结果等待超时 | 请检查网络是否通畅 |
| 18803 | 连接状态异常 | 请检查网络是否通畅 |
| 18902 | 并发超过路数限制 | |
| 18903 | 大模型规划步骤为空 | 请检查请求数据的意图是否明确 |
| 18904 | 插件未找到 | 请检查是否使用了未存在的插件 |
| 18906 | 与大模型交互次数超限制 | |
| 18907 | 运行超限制时长 | |
| 18908 | 大模型返回结果格式异常 | |
| 18951 | 同一流式大模型会话,禁止并发交互请求 | |
| 18952 | 输入文本格式或内容非法 |
#8.2 服务端错误码
| 错误码 | 错误信息 |
|---|---|
| 0 | 成功 |
| 10000 | 升级为ws出现错误 |
| 10001 | 通过ws读取用户的消息出错 |
| 10002 | 通过ws向用户发送消息 错 |
| 10003 | 用户的消息格式有错误 |
| 10004 | 用户数据的schema错误 |
| 10005 | 用户参数值有错误 |
| 10006 | 用户并发错误:当前用户已连接,同一用户不能多处同时连接。 |
| 10007 | 用户流量受限:服务正在处理用户当前的问题,需等待处理完成后再发送新的请求。(必须要等大模型完全回复之后,才能发送下一个问题) |
| 10008 | 服务容量不足,联系工作人员 |
| 10009 | 和引擎建立连接失败 |
| 10010 | 接收引擎数据的错误 |
| 10011 | 发送数据给引擎的错误 |
| 10012 | 引擎内部错误 |
| 10013 | 输入内容审核不通过,涉嫌违规,请重新调整输入内容 |
| 10014 | 输出内容涉及敏感信息,审核不通过,后续结果无法展示给用户 |
| 10015 | appid在黑名单中 |
| 10016 | appid授权类的错误。比如:未开通此功能,未开通对应版本,token不足,并发超过授权 等等 |
| 10017 | 清除历史失败 |
| 10019 | 表示本次会话内容有涉及违规信息的倾向;建议开发者收到此错误码后给用户一个输入涉及违规的提示 |
| 10110 | 服务忙,请稍后再试 |
| 10163 | 请求引擎的参数异常 引擎的schema 检查不通过 |
| 10222 | 引擎网络异常 |
| 10907 | token数量超过上限。对话历史+问题的字数太多,需要精简输入 |
| 11200 | 授权错误:该appId没有相关功能的授权 或者 业务量超过限制 |
| 11201 | 授权错误:日流控超限。超过当日最大访问量的限制 |
| 11202 | 授权错误:秒级流控超限。秒级并发超过授权路数限制 |
| 11203 | 授权错误:并发流控超限。并发路数超过授权路数限制 |
详见服务说明